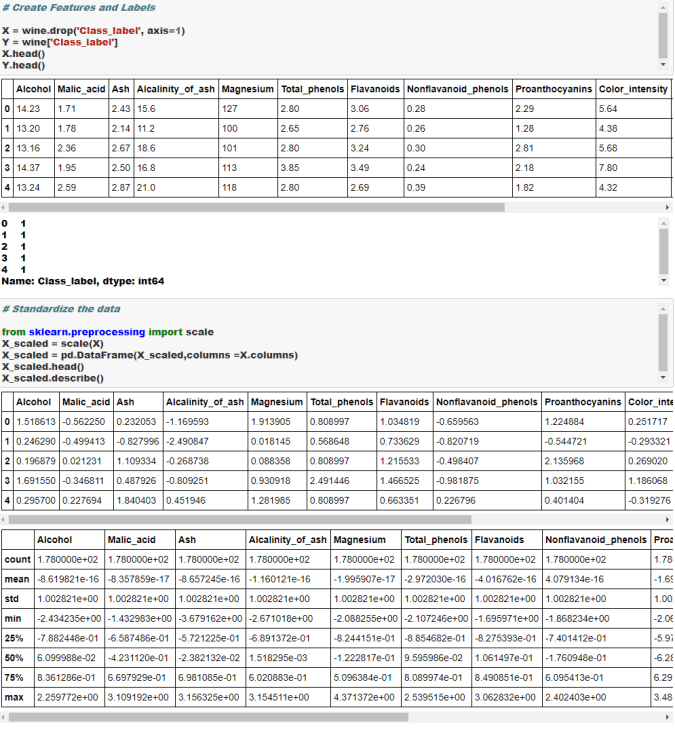
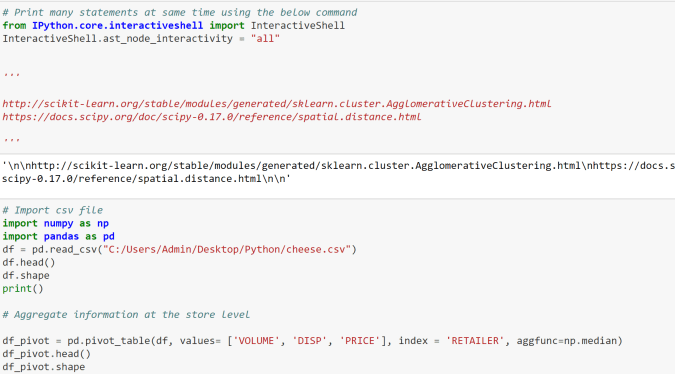
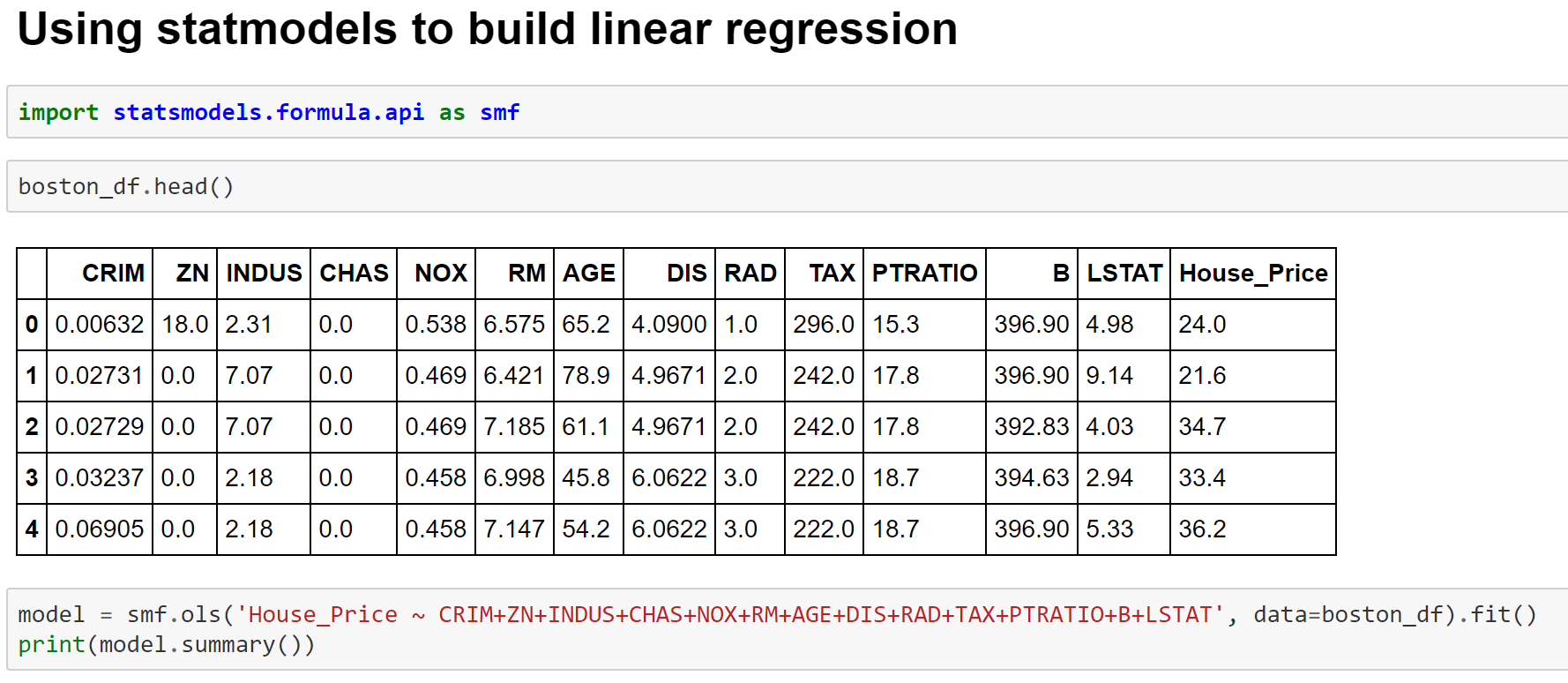
import warnings
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import seaborn as sns
from scipy import stats
from sklearn.datasets import fetch_california_housing
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_absolute_error, mean_squared_error, r2_score
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
warnings.filterwarnings("ignore")
sns.set_theme(style="whitegrid")
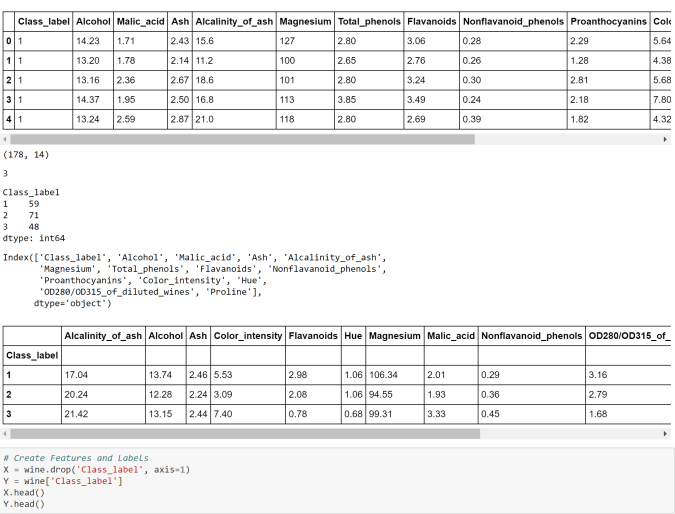
# --- Load data & EDA ---
housing = fetch_california_housing()
df = pd.DataFrame(housing.data, columns=housing.feature_names)
df["MedHouseVal"] = housing.target
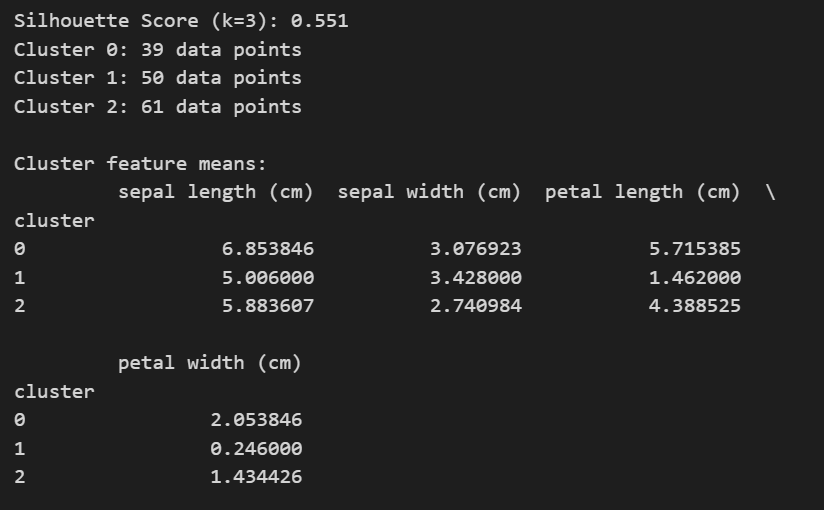
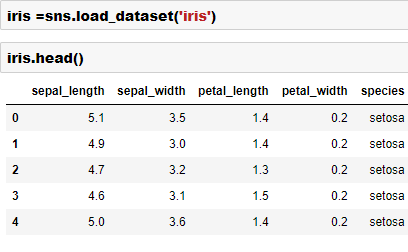
print("Shape:", df.shape)
print(df.head())
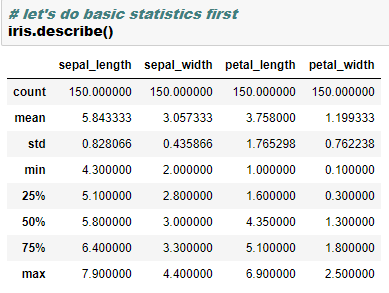
print(df.describe())
print("Missing values:\n", df.isnull().sum())
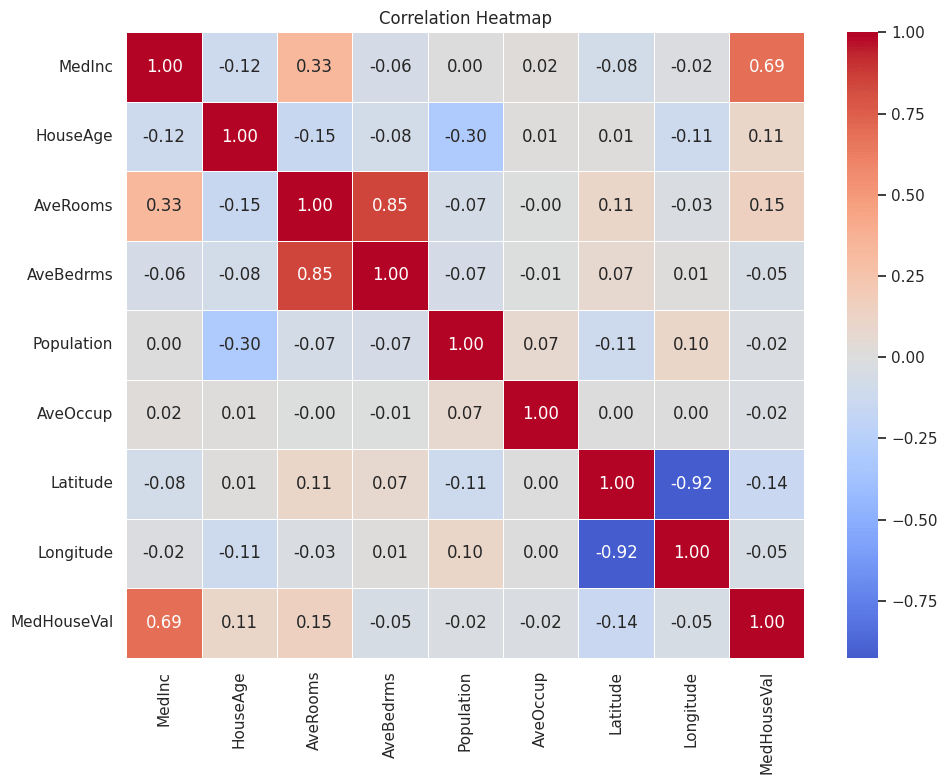
corr = df.corr()
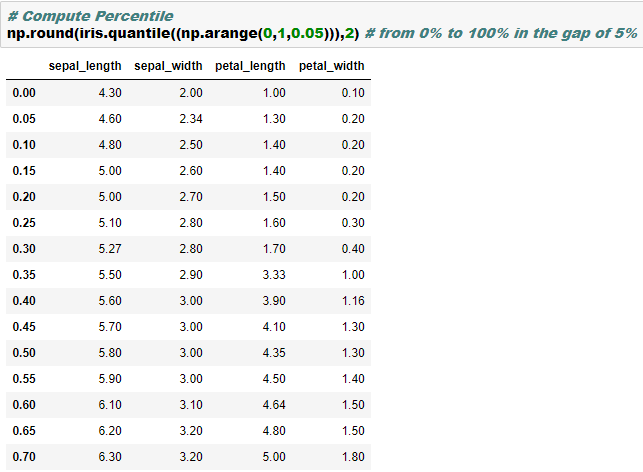
print("\nCorrelation matrix:\n", corr.round(3))
plt.figure(figsize=(10, 8))
sns.heatmap(corr, annot=True, fmt=".2f", cmap="coolwarm", center=0, linewidths=0.5)
plt.title("Correlation Heatmap")
plt.tight_layout()
plt.show()
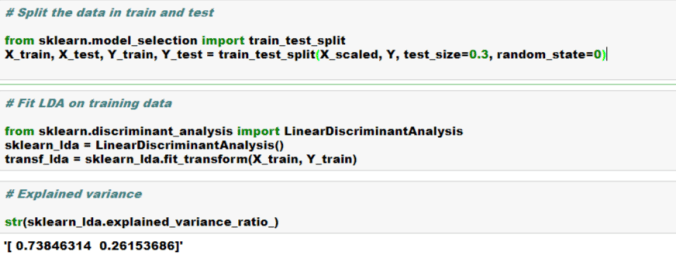
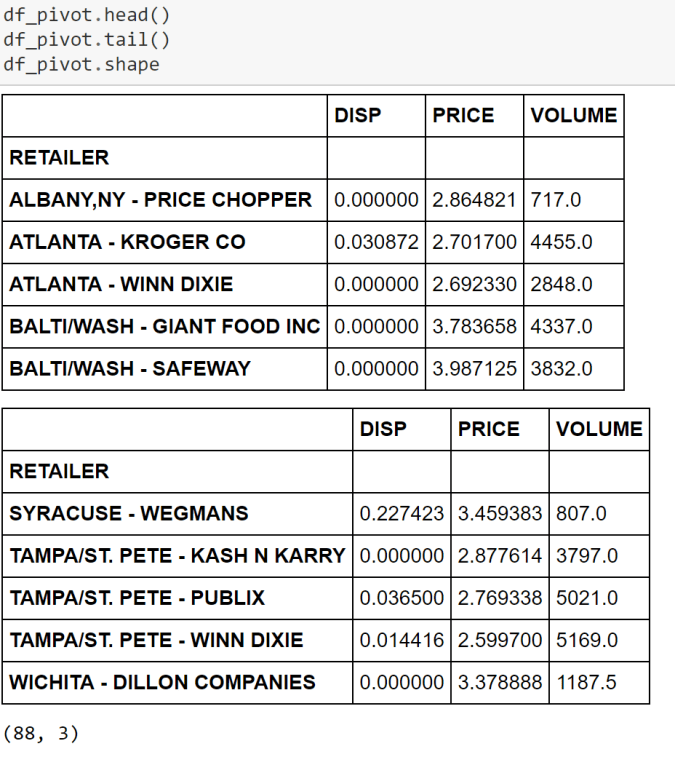
# --- STEP 1: features & label ---
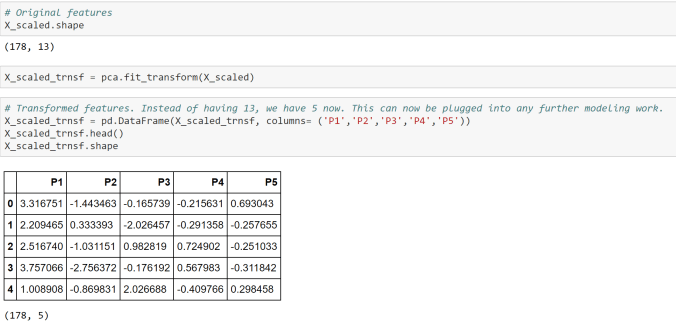
X = df.drop("MedHouseVal", axis=1)
y = df["MedHouseVal"]
# --- STEP 2: scale ---
X_scaled = pd.DataFrame(StandardScaler().fit_transform(X), columns=X.columns)
# --- STEP 3: train/test split ---
X_train, X_test, y_train, y_test = train_test_split(
X_scaled, y, test_size=0.2, random_state=42
)
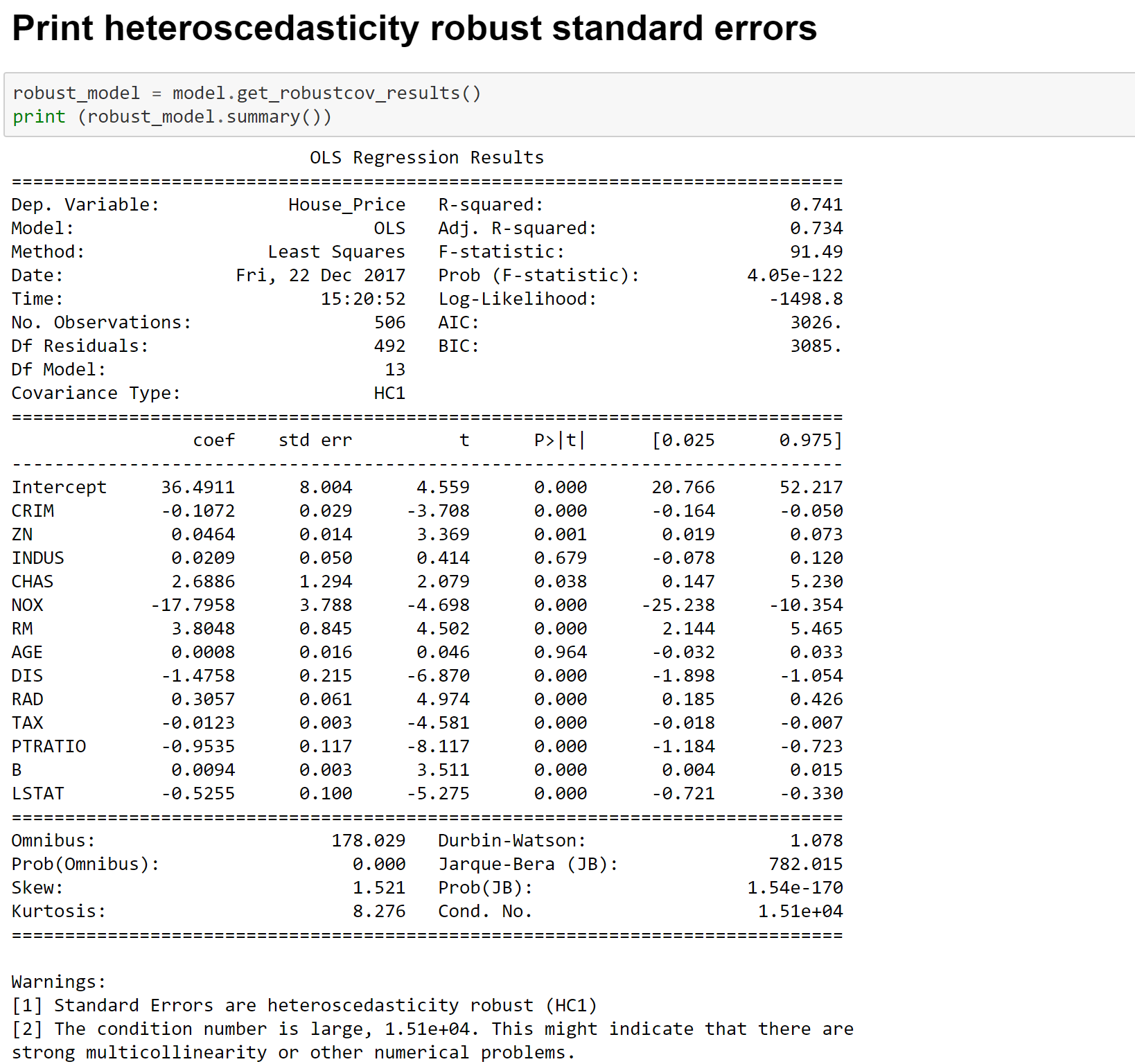
# --- STEP 4 & 5: instantiate & fit ---
model = LinearRegression()
model.fit(X_train, y_train)
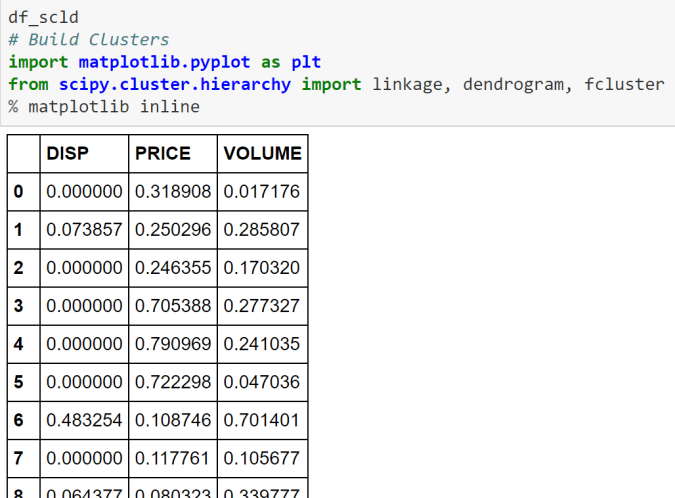
print(f"\nIntercept: {model.intercept_:.4f}")
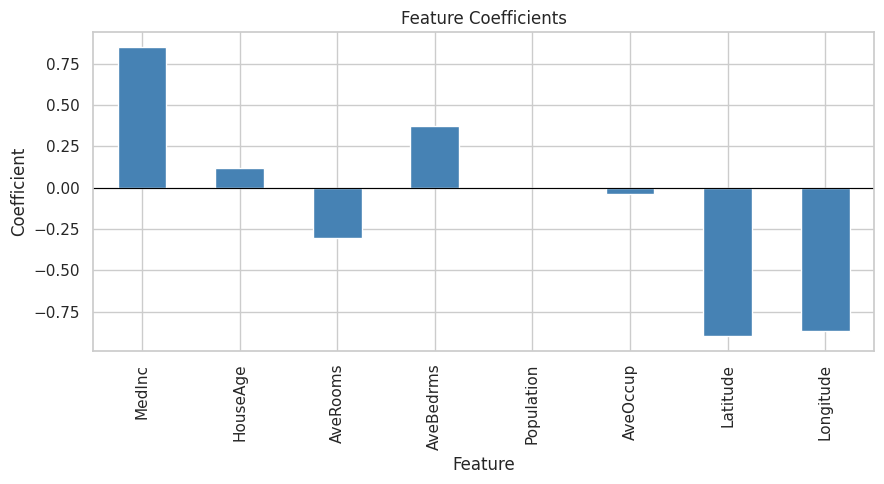
coef_df = pd.DataFrame({"Feature": X.columns, "Coefficient": model.coef_})
print(coef_df.sort_values("Coefficient", key=abs, ascending=False))
plt.figure(figsize=(9, 5))
coef_df.set_index("Feature")["Coefficient"].plot(kind="bar", color="steelblue")
plt.title("Feature Coefficients")
plt.ylabel("Coefficient")
plt.axhline(0, color="black", linewidth=0.8)
plt.tight_layout()
plt.show()
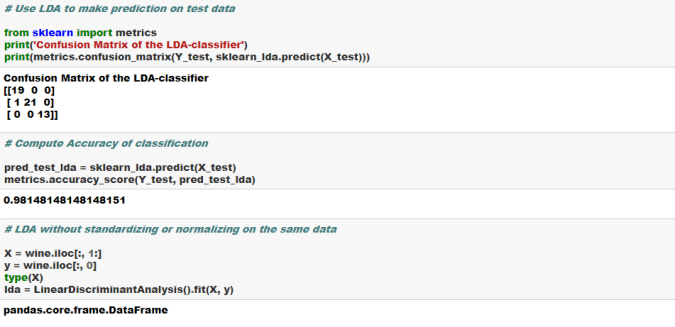
# --- STEP 6: predict & evaluate ---
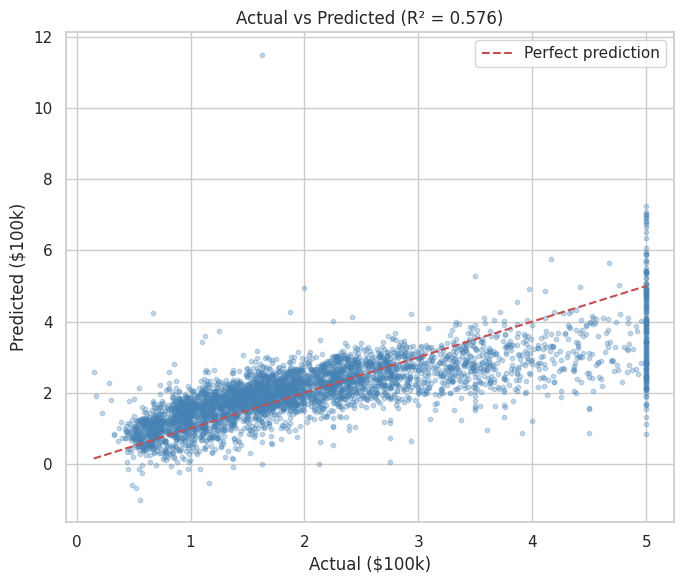
y_pred = model.predict(X_test)
r2 = r2_score(y_test, y_pred)
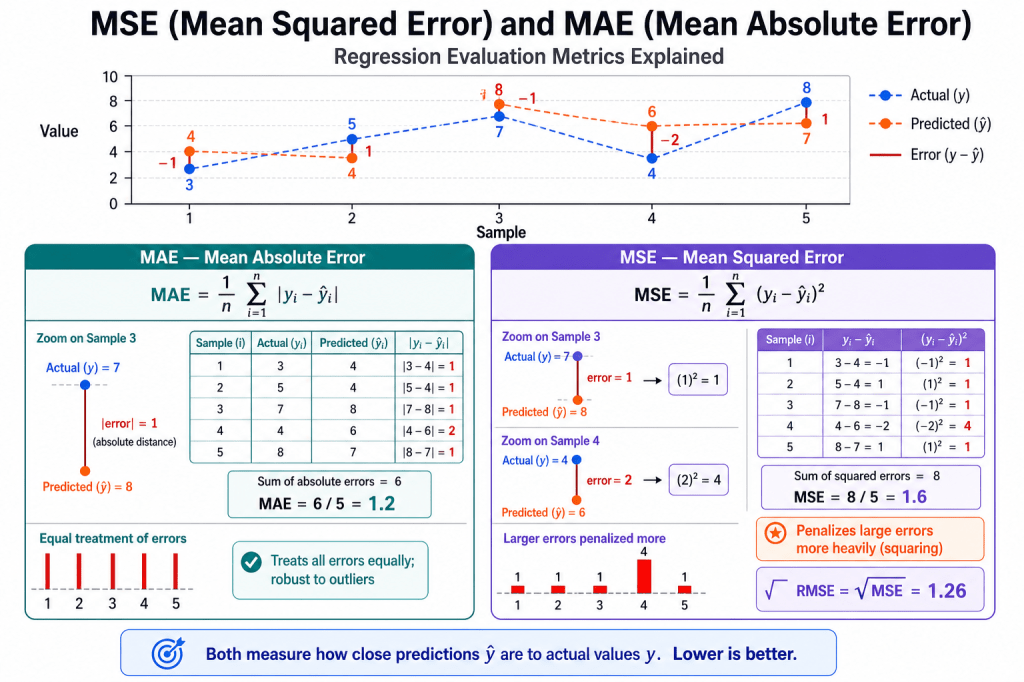
mse = mean_squared_error(y_test, y_pred)
mae = mean_absolute_error(y_test, y_pred)
print(f"\nR² : {r2:.4f}")
print(f"MSE : {mse:.4f}")
print(f"RMSE : {np.sqrt(mse):.4f}")
print(f"MAE : {mae:.4f}")
results = pd.DataFrame({
"Actual": y_test.values,
"Predicted": y_pred,
})
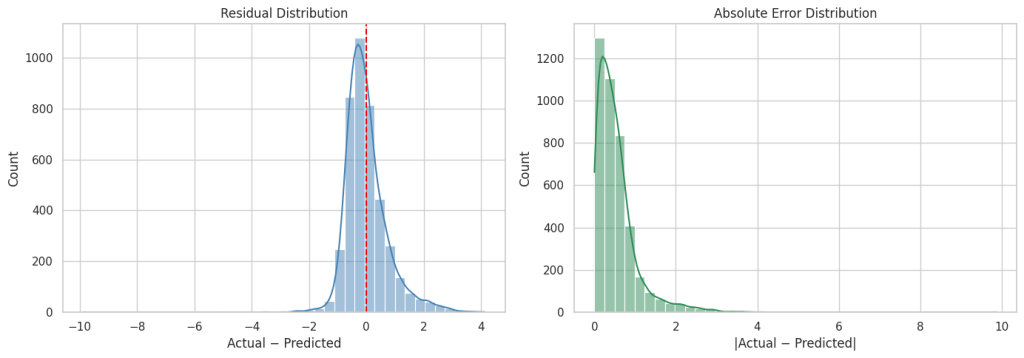
results["Error"] = results["Actual"] - results["Predicted"]
results["Abs_Error"] = results["Error"].abs()
print("\nSample results:\n", results.head(10).round(4))
print("\nError summary:\n", results[["Error", "Abs_Error"]].describe().round(4))
residuals = results["Error"]
abs_errors = results["Abs_Error"]
# Actual vs predicted
plt.figure(figsize=(7, 6))
plt.scatter(results["Actual"], results["Predicted"], alpha=0.3, s=10, color="steelblue")
lims = [results["Actual"].min(), results["Actual"].max()]
plt.plot(lims, lims, "r--", label="Perfect prediction")
plt.xlabel("Actual ($100k)")
plt.ylabel("Predicted ($100k)")
plt.title(f"Actual vs Predicted (R² = {r2:.3f})")
plt.legend()
plt.tight_layout()
plt.show()
# Error distributions
fig, axes = plt.subplots(1, 2, figsize=(14, 5))
sns.histplot(residuals, bins=40, kde=True, ax=axes[0], color="steelblue")
axes[0].axvline(0, color="red", linestyle="--")
axes[0].set_title("Residual Distribution")
axes[0].set_xlabel("Actual − Predicted")
sns.histplot(abs_errors, bins=40, kde=True, ax=axes[1], color="seagreen")
axes[1].set_title("Absolute Error Distribution")
axes[1].set_xlabel("|Actual − Predicted|")
plt.tight_layout()
plt.show()
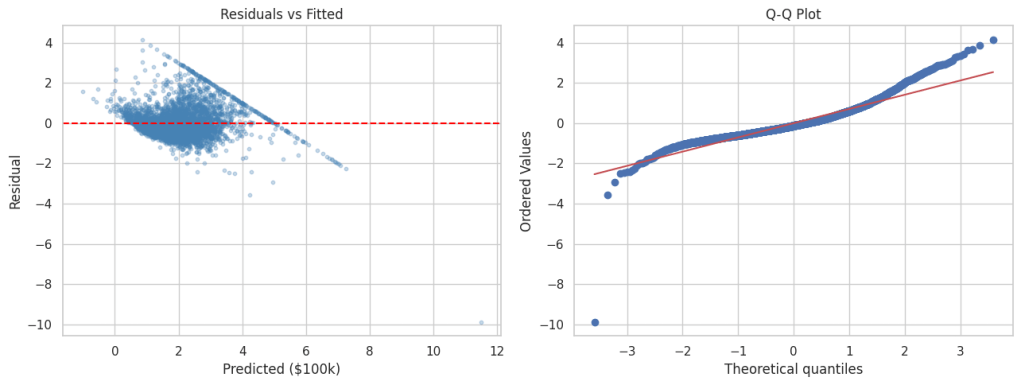
# Residuals vs fitted & Q-Q plot
fig, axes = plt.subplots(1, 2, figsize=(13, 5))
axes[0].scatter(results["Predicted"], residuals, alpha=0.3, s=10, color="steelblue")
axes[0].axhline(0, color="red", linestyle="--")
axes[0].set_xlabel("Predicted ($100k)")
axes[0].set_ylabel("Residual")
axes[0].set_title("Residuals vs Fitted")
stats.probplot(residuals, dist="norm", plot=axes[1])
axes[1].set_title("Q-Q Plot")
plt.tight_layout(
plt.show()






















































You must be logged in to post a comment.