Linear Discriminant Analysis (LDA) is similar to Principal Component Analysis (PCA) in reducing the dimensionality. However, there are certain nuances with LDA that we should be aware of-
- LDA is supervised (needs categorical dependent variable) to provide the best linear combination of original variables while providing the maximum separation among the different groups. On the other hand, PCA is unsupervised
- LDA can be used for classification also, whereas PCA is generally used for unsupervised learning
- LDA doesn’t need the numbers of discriminant to be passed on ahead of time. Generally speaking the number of discriminant will be lower of the number of variables or number of categories-1.
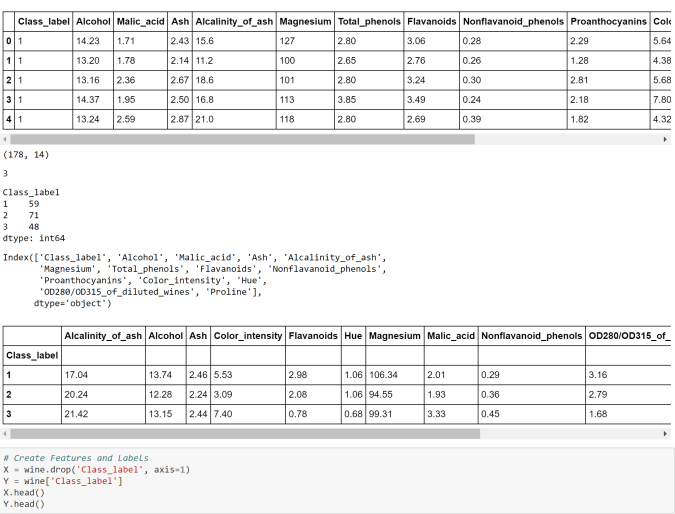
- LDA is more robust and can be conducted without even standardizing or normalizing the variables in certain cases
- LDA is preferred for bigger data sets and machine learning
Let the action begin now-

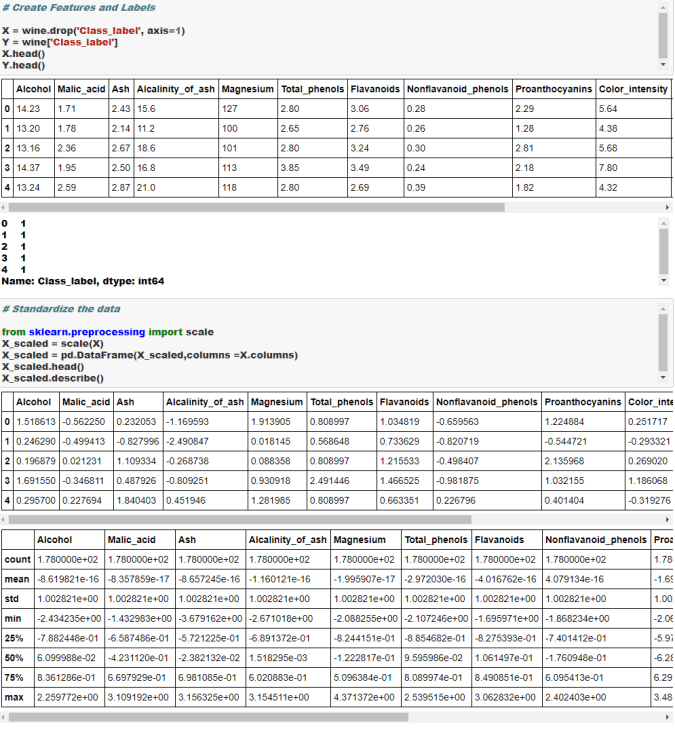
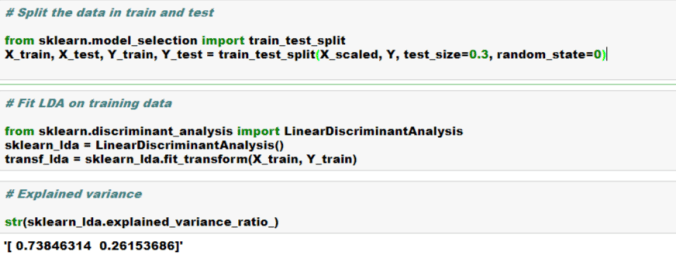
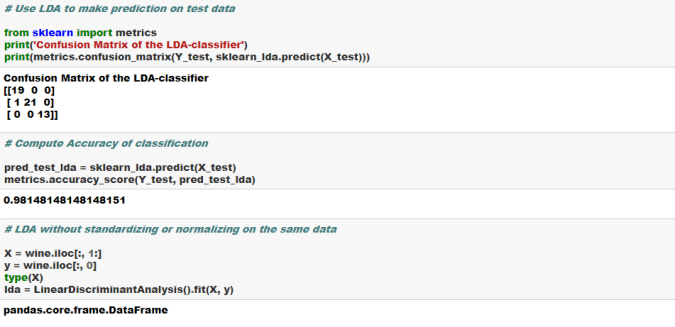

Cheers!





You must be logged in to post a comment.