What is a Recommendation Engine?
Recommendation engines or systems are machine learning algorithms to make relevant recommendations about the products and services and they are all around us. Few common examples are-
- Amazon- People who buy this also buy this or who viewed this also viewed this
- Facebook- Friends recommendation
- Linkedin- Jobs that match you or network recommendation or who viewed this profile also viewed this profile
- Netflix- Movies recommendation
- Google- news recommendation, youtube videos recommendation
Why do we have Recommendation Engines?
The main objective of these recommendation systems is to do following-
- Customization or personalizaiton
- Cross sell
- Up sell
- Customer retention
- Address the “Long Tail” phenomenon seen in Online stores vs Brick and Mortar stores
60% of video watch time on Youtube is driven by the recommendation engine.
-Google.com
How do we build a Recommendation Engine?
There are three main approaches for building any recommendation system-
- Collaborative Filtering–
Users and items matrix is built. Normally this matrix is sparse, i.e. most of the cells will be empty and hence some sort of matrix factorization ( such as SVD) is used to reduce dimensions. More on matrix factorization will be discussed later in this article.
The goal of these recommendation system is to find similarities among the users and items and recommend items which have high probability of being liked by a user given the similarities between users and items.
Similarities between users and items embeddings can be assessed using several similarity measures such as Correlation, Cosine Similarities, Jaccard Index, Hamming Distance. The most commonly used similarity measures are dotproducts, Cosine Similarity and Jaccard Index in a recommendation engine
These algorithms don’t require any domain expertise (unlike Content Based models) as it requires only a user and item matrix and related ratings/feedback and hence these algorithms can make a recommendation about an item to a user as long it can identify similar users and item in the matrix .
The flip side of these algorithms is that they may not be suitable for making recommendations about a new item that was not there in the user / item matrix on which the model was trained.
- Content Based-
This type of recommendation engine focuses on finding characteristics, attributes, tags or features of the items and recommend other items which have some of the same features. Such as, recommend another action movie to a viewer who likes action movies.
Since this algorithm uses features of a product or service to make recommendations, this offers advantage of referring unique or niche items and can be scaled to make recommendations for a wide array of users. On the other hand, defining product features accurately will be key to success of these algorithms.
- Hybrid-
These recommendation systems combine both of the above approaches.
Build Recommendation System in Python using ” Scikit – Surprise”-
Now let’s switch gears and see how we can build recommendation engines in Python using a special Python library called Surprise. In this exercise, we will build a Collaborative Filtering algorithm using Singular Value Decomposition (SVD) for dimension reduction of a large User-Item Sparse matrix to provide more robust recommendations while avoiding computational complexity.
Here is how you can get started
- Step 1- Please make sure that Anaconda and other packages such as Numpy are up to date
- Step 2- Make sure you have Visual C++ compilers installed on your system as this package requires Cython Wheels. Here are couple of links to help you in this effort


Please note that if you don’t do the Step 2 correctly, you will get errors such as shown below – ” Failed building wheel for Scikit-surprise” or ” Microsoft Visual C++ 14 is required”
- Step 3- Install Scikit- Surprise. Please make sure that you have Numpy installed before this
pip install numpy
pip install scikit-surprise
- Step 4- Import scikit-surprise and make sure it’s correctly loaded
For sake of simplicity, you can also use Google Colab to work on the below example-
Let’s import Movielens small dataset for the purpose of building couple of Recommendation Engines using KNN and SVD algorithms. Please note the that the Surprise package offers many- many more algorithms to choose from. Data can be found at the link-https://grouplens.org/datasets/movielens/

Download the zip files and you will see the following files that you can import in Python to explore. However, for the purpose of CF models, we only need the ratings.csv file.
Here are some key steps that we will follow to build Recommendation Engine for this data
- Install Scikit Surprise and Pandas Profiling Packages
- Import necessary packages
- Type Magic command to print multiple statements on a same line
- Import all files to explore data
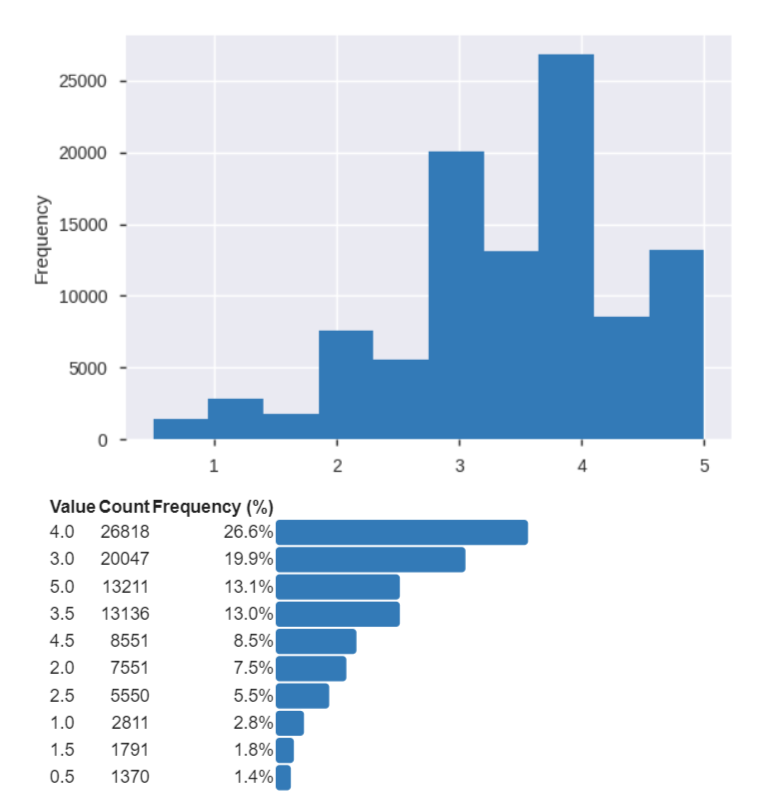
- Explore datasets using Pandas Profiling Package
- Use Reader class to parse the file correctly for Surprise package to read and process the file
- Build SVD model using cross-validation methodology
- Build SVD model using Train/Test methodology
- Make predictions of Ratings for a particular user and movie
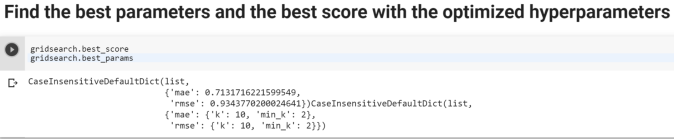
- Build KNN based Recommender and optimize hyperparameters using Gridsearch
- Find the best parameters and the best score with the optimized hyperparameters










Below are some other useful links from the Surprise Package.
Finally, here is a paper on Amazon Recommendation Engine.
Cheers!













































You must be logged in to post a comment.