Pandas is an open source Python library which create dataframes similar to Excel tables and play an instrumental role in data manipulation and data munging in any data science projects. Generally speaking, underlying data values in pandas is stored in the numpy array format as you will see shortly.
Let’s look at some examples-
First, let’s import a file (using read_csv) to work on. Then we will begin data exploration. Particularly, we will be doing following in the below example-
- Import pandas and numpy
- Import csv file
- Check type, shape, index and values of the dataframe
- Display top 5 and bottom 5 rows of the data using head() and tail()
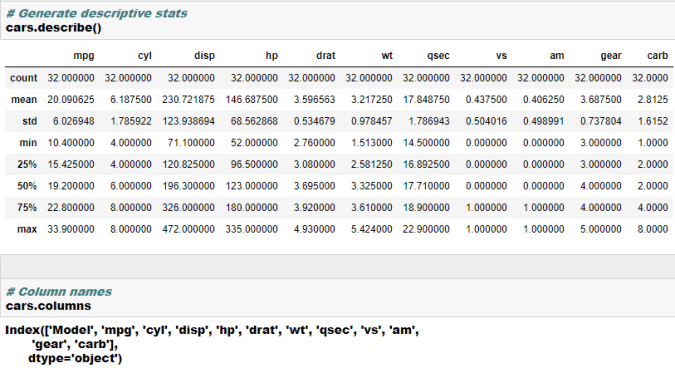
- Generate descriptive statistics such as mean, median, percentile etc
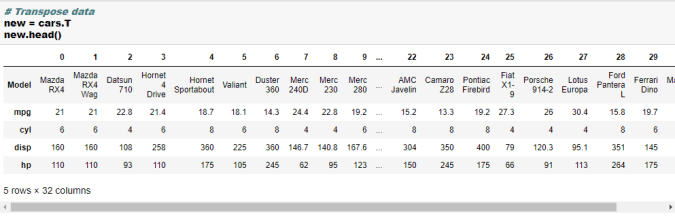
- Transpose dataframe
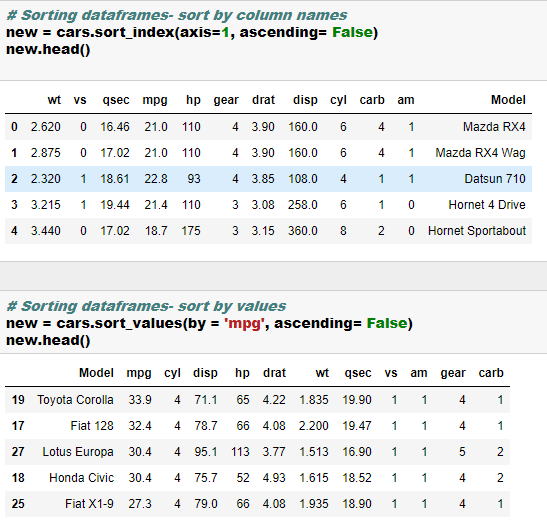
- Sort data frame by rows and columns
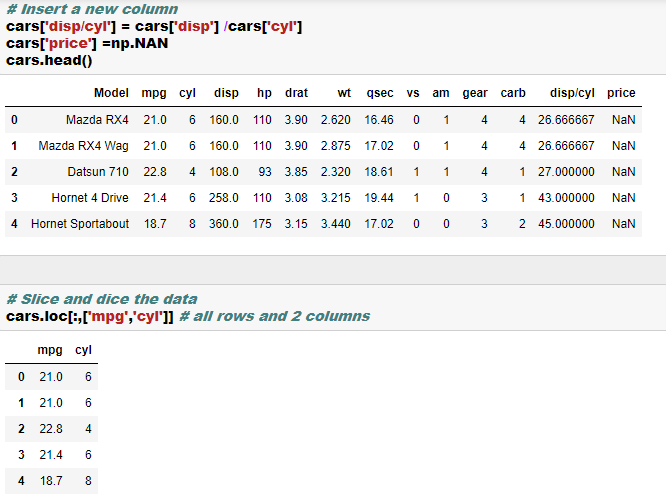
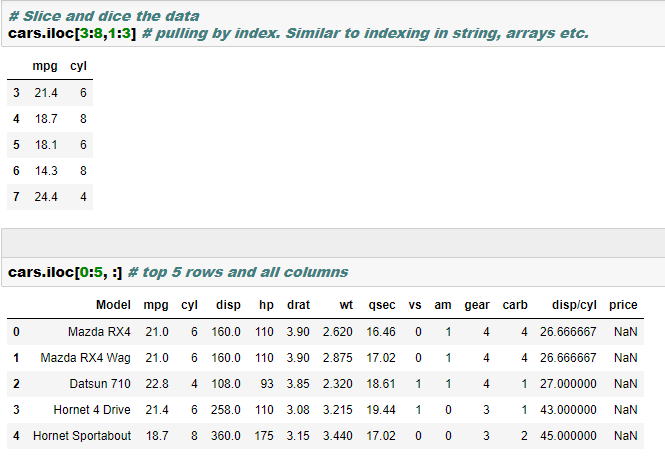
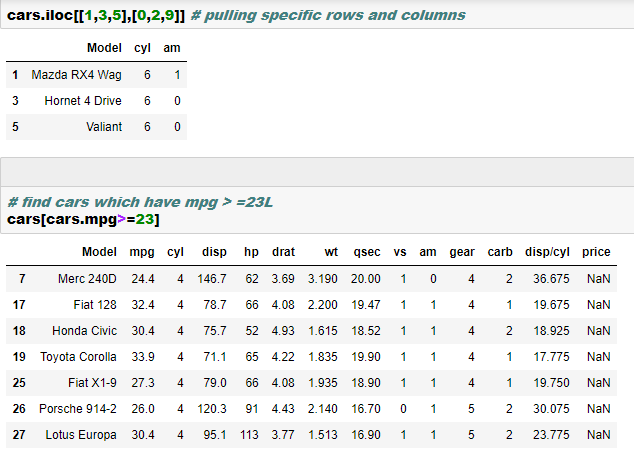
- Indexing, slicing and dicing using loc and iloc. More on this is here
- Adding new columns
- Boolean indexing
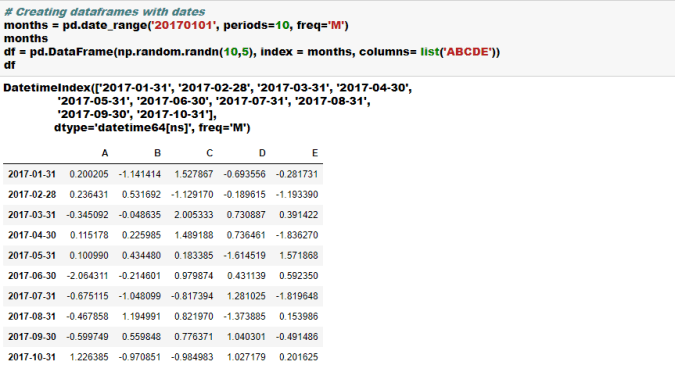
- Inserting date time in the data frame
etc.



Cheers!

Pingback: Learn Python Step by Step | RP's Blog on data science
For EXCEL files:
In [ ] :import numpy as np
import pandas as pd
superstore=pd.read_excel(‘/Users/Rakesh/Desktop/Sample – Superstore.xls’)
type(superstore)
Out [ ] :pandas.core.frame.DataFrame
LikeLike