The main objective of these recommendation systems is to do following-
Customization or personalizaiton
Cross sell
Up sell
Customer retention
Address the “Long Tail” phenomenon seen in Online stores vs Brick and Mortar stores
etc..
There are three main approaches for building any recommendation system-
Collaborative Filtering–
Users and items matrix is built. Normally this matrix is sparse, i.e. most of the cells will be empty. The goal of any recommendation system is to find similarities among the users and items and recommend items which have high probability of being liked by a user given the similarities between users and items.
Similarities between users and items can be assessed using several similarity measures such as Correlation, Cosine Similarities, Jaccard Index, Hamming Distance. The most commonly used similarity measures are Cosine Similarity and Jaccard Index in a recommendation engine
Content Based-
This type of recommendation engine focuses on finding the characteristics, attributes, tags or features of the items and recommend other items which have some of the same features. Such as recommend another action movie to a viewer who likes action movies.
Hybrid-
These recommendation systems combine both of the above approaches.
Build Recommendation System in Python using ” Scikit – Surprise”-
Now let’s switch gears and see how we can build recommendation engines in Python using a special Python library called Surprise.
This library offers all the necessary tools such as different algorithms (SVD, kNN, Matrix Factorization), in built datasets, similarity modules (Cosine, MSD, Pearson), sampling and models evaluations modules.
Here is how you can get started
Step 1- Switch to Python 2.7 Kernel, I couldn’t make it work in 3.6 and hence needed to install 2.7 as well in my Jupyter notebook environment
Step 2- Make sure you have Visual C++ compilers installed on your system as this package requires Cython Wheels. Here are couple of links to help you in this effort
Please note that if you don’t do the Step 2 correctly, you will get errors such as shown below – ” Failed building wheel for Scikit-surprise” or ” Microsoft Visual C++ 14 is required”
Step 3- Install Scikit- Surprise. Please make sure that you have Numpy installed before this
pip install numpy
pip install scikit-surprise
Step 4- Import scikit-surprise and make sure it’s correctly loaded
First of all, if you are not familiar with the concept of Market Basket Analysis (MBA), Association Rules or Affinity Analysis and related metrics such as Support, Confidence and Lift, please read this article first.
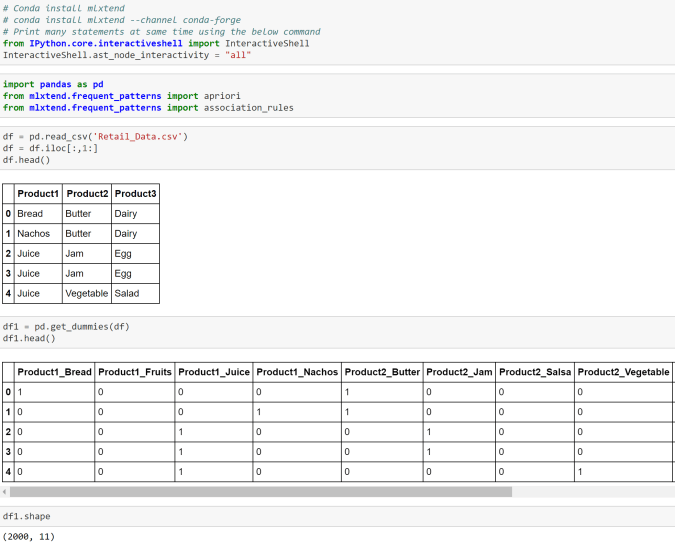
Here is how we can do it in Python. We will look at two examples-
Example 1-
Data used for this example can be found here Retail_Data.csv
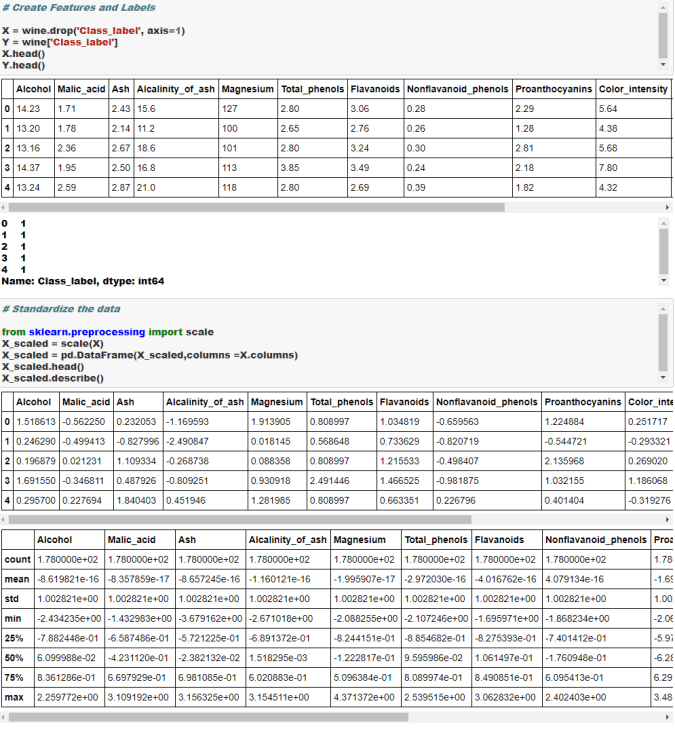
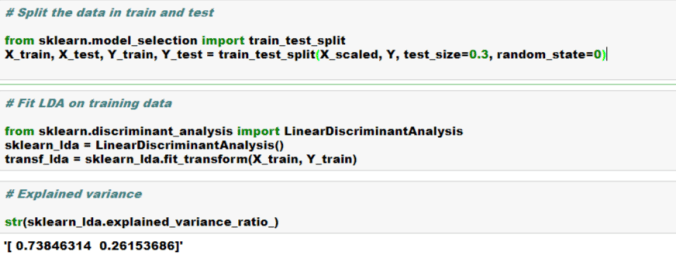
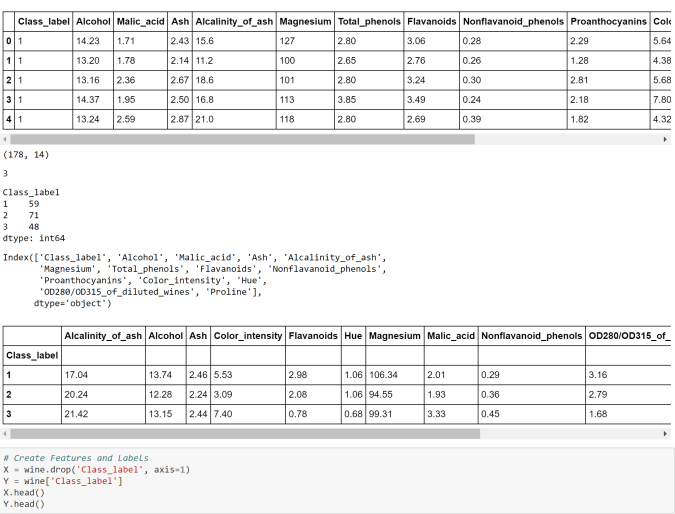
Linear Discriminant Analysis (LDA) is similar to Principal Component Analysis (PCA) in reducing the dimensionality. However, there are certain nuances with LDA that we should be aware of-
LDA is supervised (needs categorical dependent variable) to provide the best linear combination of original variables while providing the maximum separation among the different groups. On the other hand, PCA is unsupervised
LDA can be used for classification also, whereas PCA is generally used for unsupervised learning
LDA doesn’t need the numbers of discriminant to be passed on ahead of time. Generally speaking the number of discriminant will be lower of the number of variables or number of categories-1.
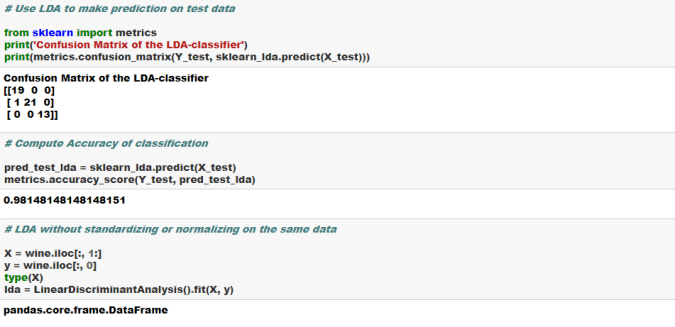
LDA is more robust and can be conducted without even standardizing or normalizing the variables in certain cases
LDA is preferred for bigger data sets and machine learning
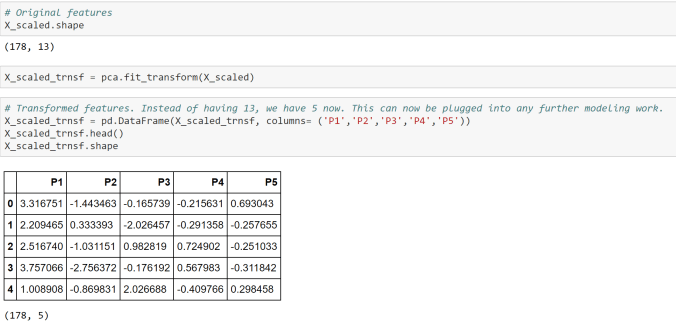
Principal Component Analysis ( PCA) is generally used as an unsupervised algorithm for reducing the data dimensions to address Curse of Dimensionality, detecting outliers, removing noise, speech recognition and other such areas.
The underlying algorithm in PCA is generally a linear algebra technique called Singular Value Decomposition (SVD). PCAs take the original data and create orthogonal components (uncorrelated components) that capture the information contained in the original data however with significantly less number of components.
Either the components themselves or key loading of the components can be plugged in any further modeling work, rather than the original data to minimize information redundancy and noise.
There are three main ways to select the right number of components-
Number of components should explain at least 80% of the original data variance or information [Preferred One]
Eigen value of each PCA component should be more than or equal to 1. This means that they should express at least one variable worth of information
Elbow or Scree method- look for the elbow in the percentage of variance explained by each components and select the components where an elbow or kink is visible.
You can use any one of the above or combination of the above to select the right number of components. It is very critical to standardize or normalize data before conducting PCA.
In the below case study we will use the first criterion shown above, i.e. 80% or more of the original data variance should be explained by the selected number of components.
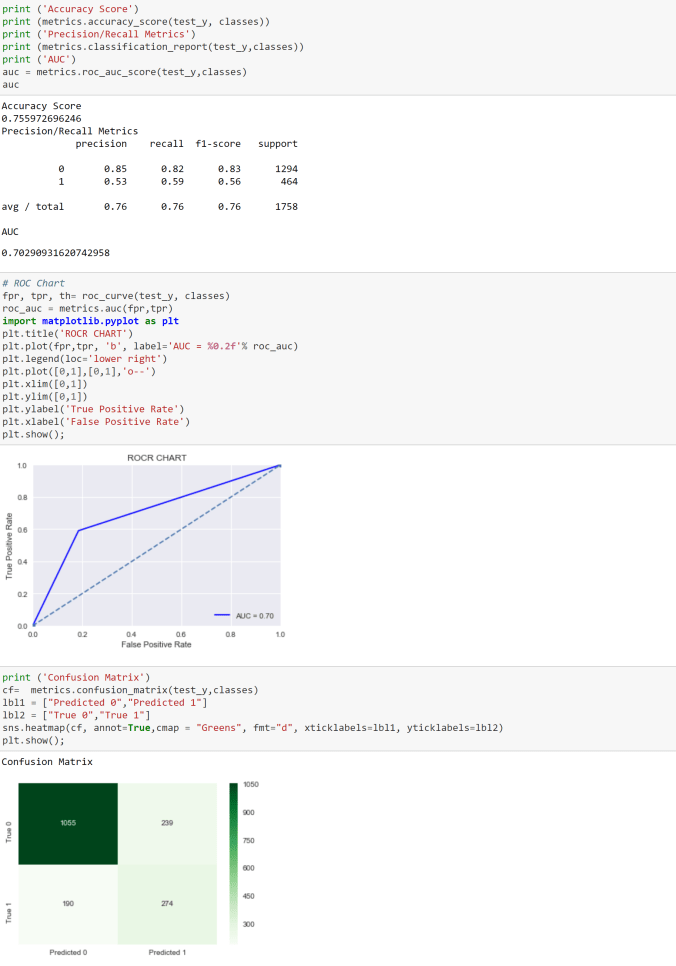
If you are not familiar with logistics regression, please read this article first. Moreover, if you are not familiar with the sklearn machine learning model building process, please read this article also.
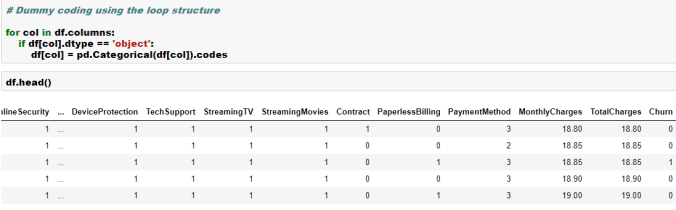
Converting categorical variables into numerical dummy coded variable is generally a requirement in machine learning libraries such as Scikit as they mostly work on numpy arrays.
In this blog, let’s look at how we can convert bunch of categorical variables into numerical dummy coded variables using four different methods-
Scikit learn preprocessing LabelEncoder
Pandas getdummies
Looping
Mapping
We will work with a dataset from IBM Watson blog as this has plenty of categorical variables. You can find the data here. In this data, we are trying to build a model to predict “churn”, which has two levels “Yes” and “No”.
We will convert the dependent variable using Scikit LabelEncoder and the independent categorical variables using Pandas getdummies. Please note that LabelEncoder will not necessarily create additional columns, whereas the getdummies will create additional columns in the data. We will see that in the below example-
Here are few other ways to dummy coding-
Here is an excellent Kaggle Kernel for detailed feature engineering.
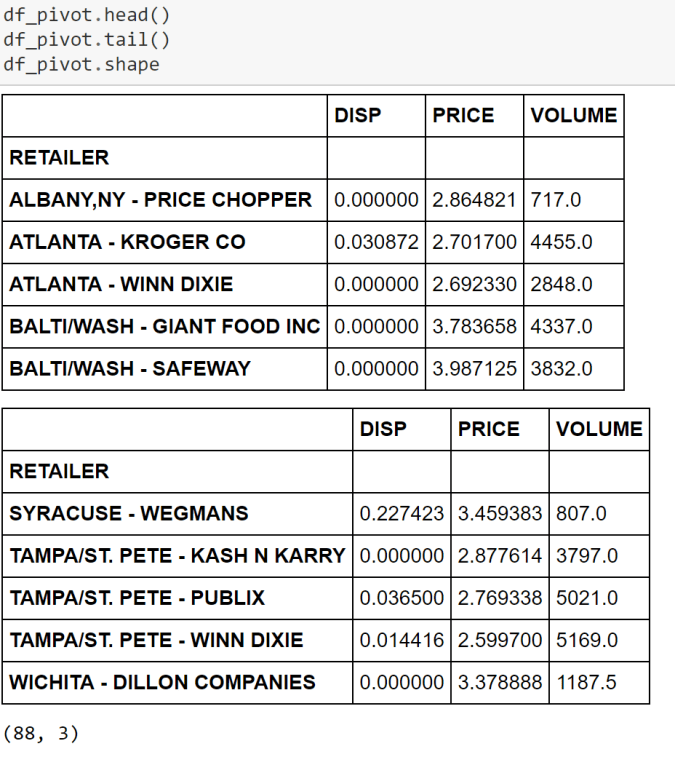
As highlighted in the article, clustering and segmentation play an instrumental role in Data Science. In this blog, we will show you how to build a Hierarchical Clustering with Python.
For this purpose, we will work with a R dataset called “Cheese”. Please install package called “Bayesm” in R and export this data set in csv format to be imported in Python. More on this dataset can be found here.
Overview: KMeans is an unsupervised machine learning algorithm used to partition data into a specified number of clusters (k). Each cluster is defined by its centroid, and the algorithm aims to minimize the distance between data points and their assigned cluster centroids.
Core Concepts:
Clusters and Centroids:
A cluster is a group of data points that are similar to each other.
The centroid is the mean position of all the points in a cluster.
Assignment and Update Steps:
Assignment: Each data point is assigned to the nearest centroid.
Update: The centroids are recalculated as the mean of all points assigned to each cluster.
Iterative Optimization:
The assignment and update steps are repeated until the centroids no longer change significantly or a maximum number of iterations is reached.
Assumptions:
The number of clusters (k) is known and fixed in advance.
Clusters are roughly spherical and equally sized.
Data points are closer to their own cluster centroid than to others.
The algorithm is sensitive to the initial placement of centroids.
Key Equations:
Distance Calculation:
The most common distance metric is Euclidean distance.
For a data point x and centroid c: Distance = sqrt( (x1 – c1)^2 + (x2 – c2)^2 + … + (xn – cn)^2 )
Centroid Update:
For each cluster, the new centroid is the mean of all points assigned to that cluster.
Centroid for cluster j: cj = (1 / Nj) * sum(xi) where Nj is the number of points in cluster j, and xi are the points in cluster j.
Objective Function (Inertia):
KMeans minimizes the sum of squared distances (inertia) between each point and its assigned centroid.
Inertia = sum over all clusters j [ sum over all points i in cluster j (distance(xi, cj))^2 ]
Algorithm Steps:
Choose k initial centroids (randomly or using a method like k-means++).
Assign each data point to the nearest centroid.
Recalculate centroids as the mean of assigned points.
Repeat steps 2 and 3 until centroids stabilize.
Limitations:
Sensitive to outliers and noise.
May converge to a local minimum (results can vary with different initializations).
Not suitable for clusters with non-spherical shapes or very different sizes.
Applications:
Market segmentation
Image compression
Document clustering
Anomaly detection
# Simple KMeans Clustering Example
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import make_blobs
from sklearn.cluster import KMeans
from sklearn.metrics import silhouette_score
# Generate synthetic data
X, y_true = make_blobs(n_samples=300, centers=4, cluster_std=0.60, random_state=42)
# Elbow method to find optimal k
inertia = []
k_range = range(1, 11)
for k in k_range:
kmeans = KMeans(n_clusters=k, random_state=42)
kmeans.fit(X)
inertia.append(kmeans.inertia_)
plt.figure(figsize=(6,4))
plt.plot(k_range, inertia, 'bo-')
plt.axvline(x=4, color='red', linestyle='--', label='Optimal k=4')
plt.xlabel('Number of clusters (k)')
plt.ylabel('Inertia')
plt.title('Elbow Method for Optimal k')
plt.legend()
plt.grid(True)
plt.show()
# Fit KMeans with optimal k (choose visually, e.g., k=4)
k_opt = 4
kmeans = KMeans(n_clusters=k_opt, random_state=42)
labels = kmeans.fit_predict(X)
# Plot clusters
plt.figure(figsize=(7,5))
plt.scatter(X[:, 0], X[:, 1], c=labels, cmap='viridis', s=50)
plt.scatter(kmeans.cluster_centers_[:, 0], kmeans.cluster_centers_[:, 1], c='red', s=200, alpha=0.75, marker='X', label='Centers')
plt.title(f'KMeans Clustering (k={k_opt})')
plt.xlabel('Feature 1')
plt.ylabel('Feature 2')
plt.legend()
plt.show()
# Silhouette score
score = silhouette_score(X, labels)
print(f'Silhouette Score (k={k_opt}): {score:.3f}')
Silhouette Score (k=4): 0.876
# KMeans Clustering on Iris Dataset
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import load_iris
from sklearn.cluster import KMeans
from sklearn.metrics import silhouette_score
import pandas as pd
# Load Iris data
iris = load_iris()
X = iris.data
# Elbow method to find optimal k
inertia = []
k_range = range(1, 11)
for k in k_range:
kmeans = KMeans(n_clusters=k, random_state=42)
kmeans.fit(X)
inertia.append(kmeans.inertia_)
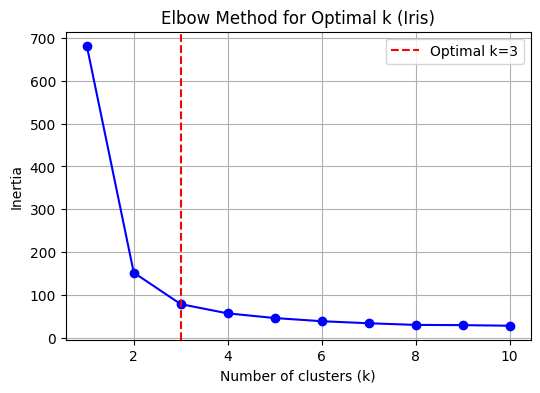
k_opt = 3 # Set optimal k explicitly for Iris data
plt.figure(figsize=(6,4))
plt.plot(k_range, inertia, 'bo-')
plt.axvline(x=k_opt, color='red', linestyle='--', label='Optimal k=3')
plt.xlabel('Number of clusters (k)')
plt.ylabel('Inertia')
plt.title('Elbow Method for Optimal k (Iris)')
plt.legend()
plt.grid(True)
plt.show()
# Fit KMeans with optimal k (choose visually, e.g., k=3)
kmeans = KMeans(n_clusters=k_opt, random_state=42)
labels = kmeans.fit_predict(X)
# Plot clusters (using first two features for visualization)
plt.figure(figsize=(7,5))
plt.scatter(X[:, 0], X[:, 1], c=labels, cmap='viridis', s=50)
plt.scatter(kmeans.cluster_centers_[:, 0], kmeans.cluster_centers_[:, 1], c='red', s=200, alpha=0.75, marker='X', label='Centers')
plt.title(f'Iris KMeans Clustering (k={k_opt})')
plt.xlabel(iris.feature_names[0])
plt.ylabel(iris.feature_names[1])
plt.legend()
plt.show()
# Plot clusters (using petal length and petal width for visualization)
plt.figure(figsize=(7,5))
plt.scatter(X[:, 2], X[:, 3], c=labels, cmap='viridis', s=50)
plt.scatter(kmeans.cluster_centers_[:, 2], kmeans.cluster_centers_[:, 3], c='red', s=200, alpha=0.75, marker='X', label='Centers')
plt.title(f'Iris KMeans Clustering (k={k_opt}) - Petal Length vs Petal Width')
plt.xlabel(iris.feature_names[2])
plt.ylabel(iris.feature_names[3])
plt.legend()
plt.show()
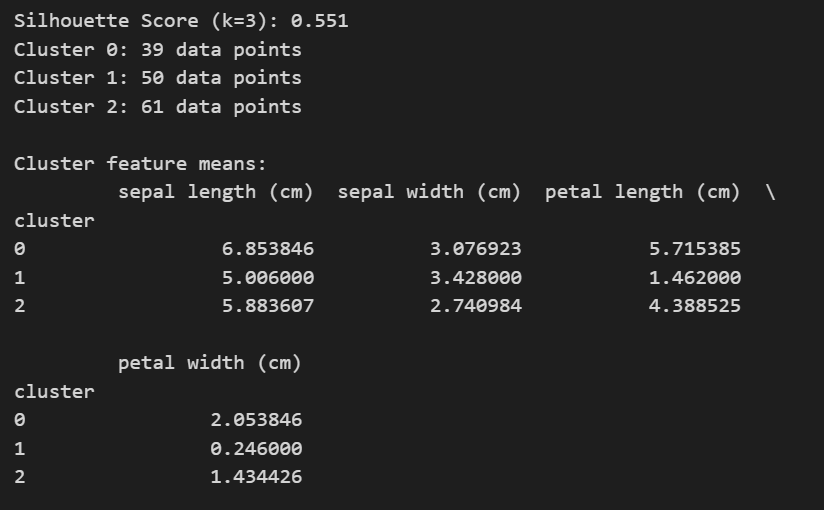
# Silhouette score
score = silhouette_score(X, labels)
print(f'Silhouette Score (k={k_opt}): {score:.3f}')
# Number of observations in each cluster
unique, counts = np.unique(labels, return_counts=True)
for i, count in zip(unique, counts):
print(f"Cluster {i}: {count} data points")
# Descriptive summary of each cluster (mean feature values)
df = pd.DataFrame(X, columns=iris.feature_names)
df['cluster'] = labels
print("\nCluster feature means:")
print(df.groupby('cluster').mean())







































You must be logged in to post a comment.